


Python continua sendo uma das linguagens mais versáteis para desenvolvimento de software.
E em pleno 2025, algumas bibliotecas/frameworks se tornam parte de um canivete suíço para quem desenvolve na linguagem das cobras, principalmente se você tem o intuito de construir aplicações eficientes e robustas.
Neste artigo, você conhecerá 3 ferramentas essenciais para dominar nesse ano, com exemplos práticos para que você possa começar a usá-las agora mesmo!
Observação: Todos os links de referências estão espalhados pelo artigo nas palavras chave.
1 - Fast API
O FastAPI tem se destacado como um dos frameworks mais eficientes para a construção de API’s REST em Python. Ele é projetado para oferecer alta performance, batendo pau a pau com outros frameworks (procure por fastapi nesse benchmark) e várias facilidades como documentação em OpenAPI e processamento assíncrono.
Além disso, o FastAPI é um concorrente direto do Flask, onde nesse artigo você pode ver as principais vantagens/desvantagens e diferenças entre eles. Abaixo, um breve resumo de algumas vantagens do FastAPI sobre o Flask:
| Recurso | Flask | FastAPI |
| Performance | Baixa (Single-thread) | Alta (Assíncrono e baseado em Starlette) |
| Suporte a Tipagem | Não nativo | Sim, aproveitando recursos modernos do Python |
| Validação de Dados | Precisa de bibliotecas extras | Usa Pydantic nativamente |
| Documentação Automática | Requer configurações extras | Gera documentação OpenAPI automaticamente |
Instalação
Para instalar o FastAPI basta executar esse comando:
pip install "fastapi[standard]"
Exemplo
O menor código para você conseguir rodar uma API usando esse framework, é criando um arquivo fastapi_example.py com o seguinte código:
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
Observe que na frente da definição das funções (def), temos o async que faz com que o processamento dessa função se torne assíncrono, é realmente simples assim usar essa funcionalidade e tornar a seu código muito mais rápido do que o Flask.
Agora, para rodar o código, é necessário utilizar o seguinte comando:
fastapi dev fastapi_example.py
O comando tem a seguinte estrutura:
fastapi dev <nome_do_arquivo_python>, se você criou um arquivo chamadoapp.py, então você deve executar o comando:fastapi dev app.py
Para testar se sua API está funcionando, execute esse comando:
curl --location 'http://localhost:8000'
Com isso você deve receber um JSON com o seguinte conteúdo:
{"Hello": "World"}
2 - Pydantic
Quando trabalhamos com API’s, é essencial garantir que os dados recebidos e enviados estejam corretos.
O Pydantic resolve esse problema de forma eficiente, trazendo um sistema de validação baseado em “tipagem estática” . Essa biblioteca permite definir modelos de dados que validam automaticamente as entradas, geram erros quando algo está incorreto e ainda melhoram a legibilidade do código.
Basicamente a biblioteca impede que erros de Runtime aconteçam por conta de atribuições indevidas:
class User:
name: str
u = User()
u.name = None # <-- Não deveria ser possível atribuir o valor 'None' ao tipo str. Isso é possível por conta da tipagem dinâmica do Python
print(u.name.upper()) # <-- Gera um erro, pois u.Name assume o valor None. None não tem o atributo 'upper'
"""
ERROR!
Traceback (most recent call last):
File "<main.py>", line 7, in <module>
AttributeError: 'NoneType' object has no attribute 'upper'
"""
O Pydantic também é usado no FastAPI, então ao definir um modelo com Pydantic, o FastAPI automaticamente valida os dados recebidos e gera documentação em OpenAPI.
Porém, o uso do Pydantic não se limita somente ao FastAPI, você pode usar ele em qualquer lugar do seu código para garantir que um modelo de dados/classe seja íntegro(a) durante a execução do programa, tornando seu código muito Robusto.
Inclusive, essa dica foi baseada nesse Livro: https://amzn.to/3EyBF1a, que é super recomendado para você que trabalha com Python.
Instalação
Para instalar o Pydantic, basta executar o seguinte comando:
pip install pydantic
Exemplo
O menor exemplo de código que podemos ter para executar o Pydantic é:
from datetime import datetime
from pydantic import BaseModel, PositiveInt, ValidationError
class User(BaseModel):
id: int
name: str = "John Doe"
signup_ts: datetime | None
tastes: dict[str, PositiveInt]
external_data = {
"id": 123,
"signup_ts": "2019-06-01 12:22",
"tastes": {
"wine": 9,
b"cheese": 7,
"cabbage": "1",
},
}
user = User(**external_data)
print("---------------- Success ----------------")
print(user.id)
print(user.model_dump())
incorrect_external_data = {"id": "not an int", "tastes": {}}
try:
User(**incorrect_external_data)
except ValidationError as e:
print("---------------- Error ----------------")
print(e.errors())
Nesse exemplo de código, vamos ter essa saída:
---------------- Success ----------------
123
{'id': 123, 'name': 'John Doe', 'signup_ts': datetime.datetime(2019, 6, 1, 12, 22), 'tastes': {'wine': 9, 'cheese': 7, 'cabbage': 1}}
---------------- Error ----------------
[{'type': 'int_parsing', 'loc': ('id',), 'msg': 'Input should be a valid integer, unable to parse string as an integer', 'input': 'not an int', 'url': 'https://errors.pydantic.dev/2.10/v/int_parsing'}, {'type': 'missing', 'loc': ('signup_ts',), 'msg': 'Field required', 'input': {'id': 'not an int', 'tastes': {}}, 'url': 'https://errors.pydantic.dev/2.10/v/missing'}]
Perceba que a propriedade id na variável incorrect_external_data , é uma string e não um inteiro e por isso uma exception é levantada, já que a validação do modelo falhou.
Exemplo com o FastAPI
Aqui está um exemplo de uma API que recebe os dados de um usuário e valida automaticamente as informações usando Pydantic:
from datetime import datetime
from typing import Optional
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, PositiveInt
class User(BaseModel):
id: Optional[PositiveInt] = None
name: str = "John Doe"
signup_ts: datetime | None
tastes: dict[str, PositiveInt]
app = FastAPI()
users: dict[int, User] = {}
@app.post("/users")
async def insert_user(user: User):
id = len(users) + 1
user.id = id
users[id] = user
return {"id": user.id}
@app.get("/users/{user_id}")
async def read_users(user_id: int):
try:
user = users[user_id]
return user
except KeyError:
raise HTTPException(status_code=404, detail="user not found")
Execute esse comando para inserir um usuário na API:
curl --location 'http://localhost:8000/users' \
--header 'Content-Type: application/json' \
--data '{
"signup_ts": "2025-02-14 12:22",
"name": "Test User",
"tastes": {
"wine": 9,
"cheese": 7,
"cabbage": 1
}
}'
Esse comando vai retornar um JSON com o ID do usuário inserido:
{"id": 1}
Agora, basta executar o comando abaixo para obter o usuário inserido:
curl --location 'http://localhost:8000/users/1'
Agora vem a mágica! Ao executar esse comando, em que a propriedade name não é uma string, a validação do modelo ocorre automaticamente, retornando um erro:
curl --location 'http://localhost:8000/users' \
--header 'Content-Type: application/json' \
--data '{
"signup_ts": "2025-02-14 12:22",
"name": 1,
"tastes": {
"wine": 9,
"cheese": 7,
"cabbage": 1
}
}'
Resposta de erro retornada que contém os detalhes da validação:
{
"detail": [
{
"type": "string_type",
"loc": [
"body",
"name"
],
"msg": "Input should be a valid string",
"input": 1
}
]
}
O Pydantic facilita muito o trabalho com dados estruturados e, quando combinado com o FastAPI, te permite construir uma API confiável em tempo recorde.
Não esqueça de usar o Pydantic para validar seus outros modelos em seu código!
3 - Polars
Você que trabalha com data Science, eu não esqueci de você ! Quando falamos de manipulação de dados no Python, a primeira biblioteca que vem à mente geralmente é o Pandas (O famoso import pandas as pd). No entanto, conforme os datasets crescem, o Pandas pode se tornar um gargalo de performance. É aqui que o Polars se destaca.
O Polars é uma biblioteca de processamento de dados otimizado que foi projetado para ser extremamente rápido e eficiente, aproveitando processamento paralelo e técnicas de otimização.
Ele usa uma estrutura baseada em colunas, semelhante ao Apache Arrow, tornando-o ideal para trabalhar com grandes volumes de dados sem comprometer a performance.
Um de seus destaques, é que você pode utilizar a GPU para tornar o processamento ainda mais rápido:
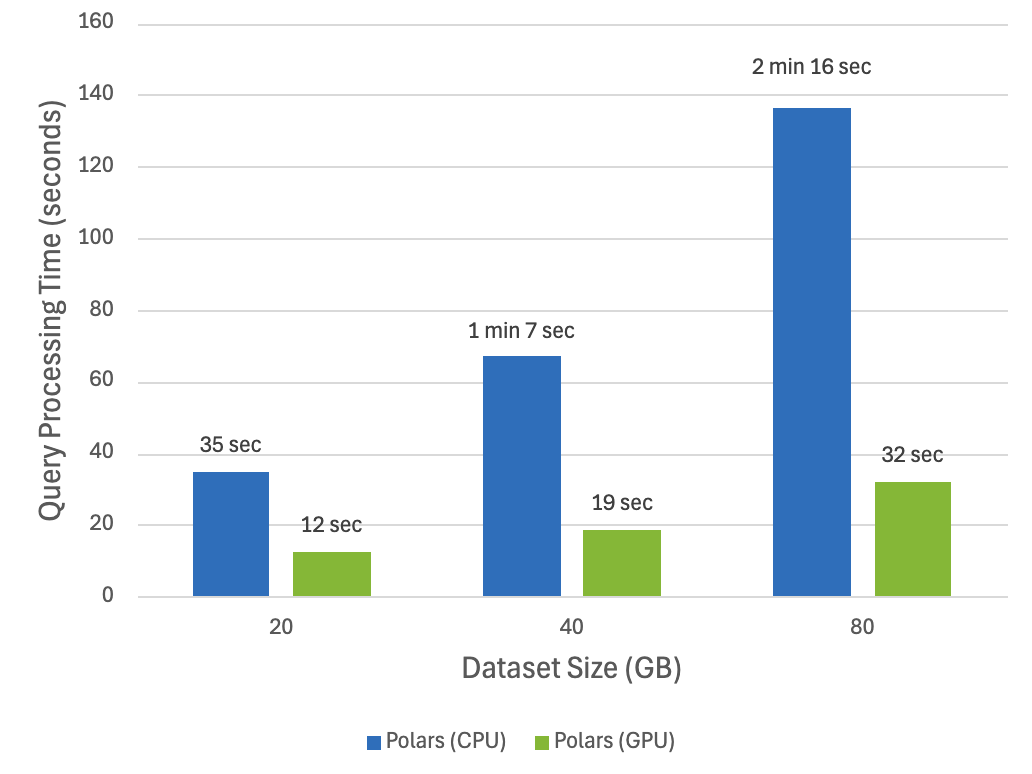
Essa imagem foi obtida desse site: https://docs.rapids.ai/api/cudf/stable/cudf_polars/, mas se você gostaria de tirar as conclusões por você mesmo, recomendo você executar esse Google Colab, com o ambiente de execução configurado com uma GPU.
E Por que usar Polars em vez de Pandas? Bom, aqui vão alguns motivos:
Mais rápido: Operações em grandes datasets são significativamente mais rápidas devido ao processamento paralelo.
Menos consumo de memória: A arquitetura em colunas reduz o uso de RAM.
API intuitiva: Oferece uma sintaxe semelhante ao Pandas, mas com melhorias.
Suporte a Lazy Evaluation: Permite executar operações de forma otimizada, processando apenas os dados necessários.
Instalação
Para instalar o Polars basta executar o seguinte comando:
pip install polars
Para instalar a versão que roda em GPU, sugiro a a utilização no
Python 3.11, já que no3.13tive alguns problemas com compatibilidade de dependências.
Para instalar o backend de GPU, o comando que funcionou para a instalação na máquina de testes, foi esse:
pip install polars cudf-polars-cu12
Mas, vou deixar uma lista de links que podem ser úteis para você rodar o Polars usando sua GPU:
Documentação do Nvidia-SMI (Para monitoramento da placa de vídeo)
Exemplo
Primeiro, faça o download do dataset mais comum de todos, o Iris: https://github.com/pola-rs/polars/blob/main/docs/assets/data/iris.csv
Em seguida, salve ele com o nome iris.csv no MESMO DIRETÓRIO DO SEU ARQUIVO PYTHON.
import polars as pl
q = (
pl.scan_csv("iris.csv")
.filter(pl.col("sepal_length") > 5)
.group_by("species")
.agg(pl.all().sum())
)
df = q.collect()
Exemplo Polars vs Pandas
Se você ainda está em dúvida que o Polars consegue bater o pandas, então eu resolvi montar um teste que compara os dois.
Para isso, será necessário baixar um CSV um pouco maior (aprox. 500 MB), o arquivo 5m Sales Records desse site https://excelbianalytics.com/wp/downloads-18-sample-csv-files-data-sets-for-testing-sales/.
Em seguida, será necessário instalar o pandas:
pip install pandas
E executar o seguinte código:
import time
import pandas as pd
import polars as pl
csv_file = "5m Sales Records.csv"
group_by_column = "Region"
sort_column = "Unit Price"
def measure_time(func, *args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
return result, end - start
def pandas_test():
df = pd.read_csv(csv_file)
df_filtered = df[df[sort_column] > 30]
df_grouped = df.groupby(group_by_column).agg({sort_column: "sum"})
df_sorted = df.sort_values(by=sort_column, ascending=False)
df_sorted.to_csv("output_pandas.csv", index=False)
def polars_test():
df = pl.read_csv(csv_file)
df_filtered = df.filter(df[sort_column] > 30)
df_grouped = df.group_by(group_by_column).agg(pl.col(sort_column).sum())
df_sorted = df.sort(sort_column, descending=True)
df_sorted.write_csv("output_polars.csv")
_, polars_time = measure_time(polars_test)
print(f"Polars: {polars_time:.4f} secs")
_, pandas_time = measure_time(pandas_test)
print(f"Pandas: {pandas_time:.4f} secs")
O código vai realizar uma pequena série de processamento com o dataset (filtragem, agrupamento com agregação de soma, ordenação) e por fim, salvar o dataset em um novo arquivo CSV, imprimindo o tempo de execução no terminal.
Ao executar esse código, foi possível obter o seguinte resultado:
Polars: 2.4661 secs
Pandas: 33.0203 secs
Observação: O tempo de processamento pode variar de acordo com o ambiente de execução.
Tire suas próprias conclusões, mas, eu daria uma chance para o Polars no próximo projeto de Data Science.
Conclusão
Aprender e dominar essas três bibliotecas em 2025 vai acelerar seu desenvolvimento e torná-lo um programador mais eficiente. A combinação de FastAPI e Pydantic é especialmente poderosa pra construir API’s robustas e o Polars é feito para quem precisa de performance sem abrir mão de usar Python.
Se você quiser mais conteúdos como esse, continue acompanhando nossas publicações e compartilhe com outros garotos/garotas de programa! 🚀